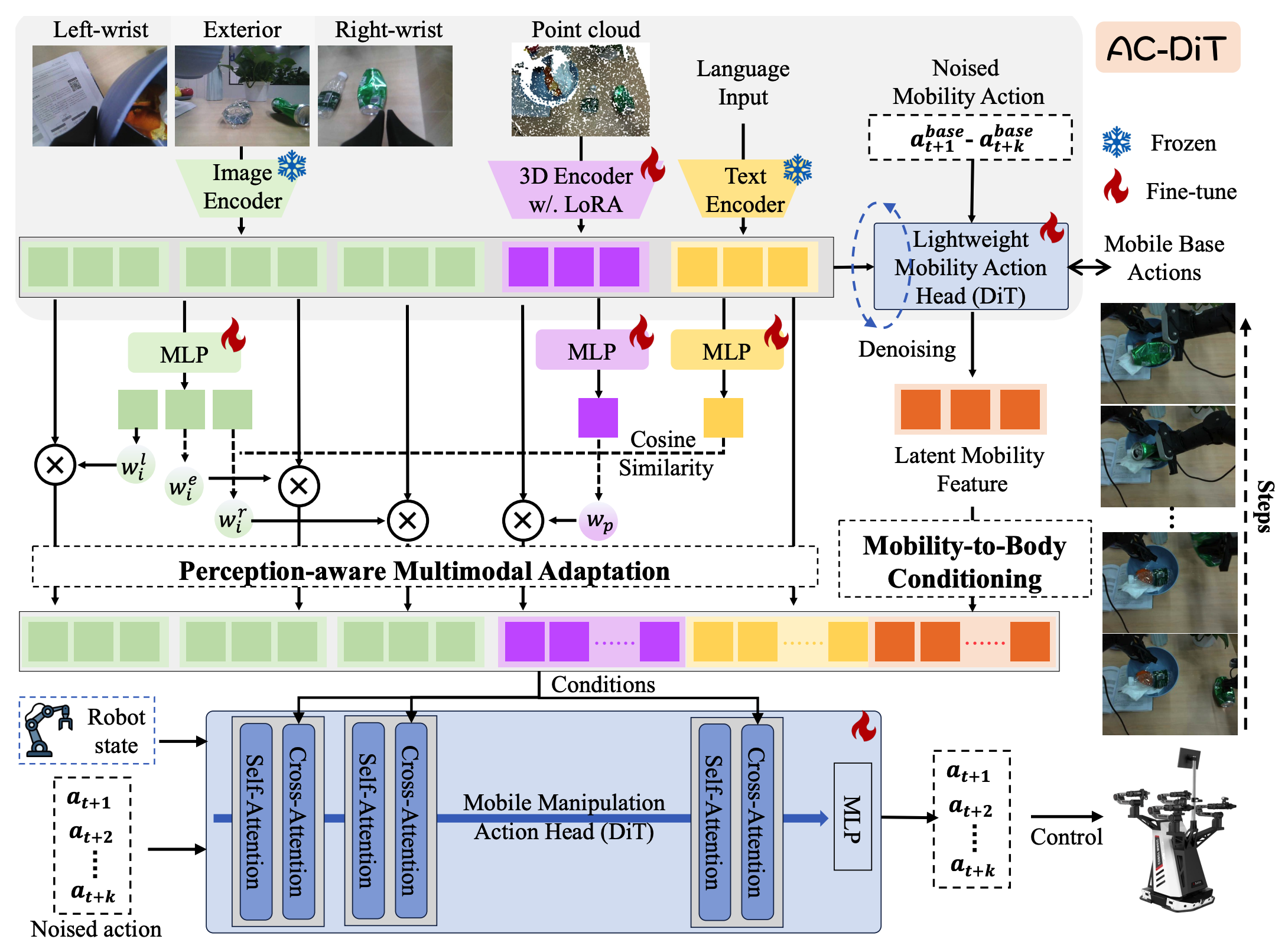
We propose AC-DiT, an end-to-end vision-language-action model framework for mobile manipulation. It features a two-stage action generation mechanism (coarse prediction + diffusion refinement) and achieves significantly better performance on multiple benchmarks and real-robot experiments compared to existing methods.
@inproceedings{chen2025acdit,title={AC-DiT: Adaptive Coordination Diffusion Transformer for Mobile Manipulation},author={Chen, Sixiang and Liu, Jiaming and Qian, Siyuan and Jiang, Han and Li, Lily and Zhang, Renrui and Liu, Zhuoyang and Gu, Chenyang and Hou, Chengkai and Wang, Pengwei and Wang, Zhongyuan and Zhang, Shanghang},booktitle={Neural Information Processing Systems (NeurIPS)},year={2025},}
RSS 2025
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Kun Wu*, Chengkai Hou*, Jiaming Liu*, Zhengping Che*, Xiaozhu Ju*, ..., Siyuan Qian, Shanghang Zhang, and Jian Tang
We propose RoboMIND, a multi-embodiment robot teleoperation dataset covering 107K demonstration trajectories, 479 tasks, 96 object categories, and 4 robot morphologies, including failure cases and digital twin environments. Experiments verify that it significantly improves VLA model success rates and generalization capabilities, making it one of the largest and highest-quality datasets of its kind.
@inproceedings{wu2025robomind,title={RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation},author={Wu, Kun and Hou, Chengkai and Liu, Jiaming and Che, Zhengping and Ju, Xiaozhu and Yang, Zhuqin and Li, Meng and Zhao, Yinuo and Xu, Zhiyuan and Yang, Guang and Fan, Shichao and Wang, Xinhua and Liao, Fei and Zhao, Zhen and Li, Guangyu and Jin, Zhao and Wang, Lecheng and Mao, Jilei and Liu, Ning and Ren, Pei and Zhang, Qiang and Lyu, Yaoxu and Liu, Mengzhen and He, Jingyang and Luo, Yulin and Gao, Zeyu and Li, Chenxuan and Gu, Chenyang and Fu, Yankai and Wu, Di and Wang, Xingyu and Chen, Sixiang and Wang, Zhenyu and An, Pengju and Qian, Siyuan and Zhang, Shanghang and Tang, Jian},booktitle={Robotics: Science and Systems (RSS)},year={2025},publisher={Robotics: Science and Systems Foundation},}
Nat. Comput. Sci.
Implicit Neural Image Field for Biological Microscopy Image Compression
Gaole Dai, ..., Siyuan Qian, Ming Lu, Ali Ata Tuz, and Matthias Gunzer
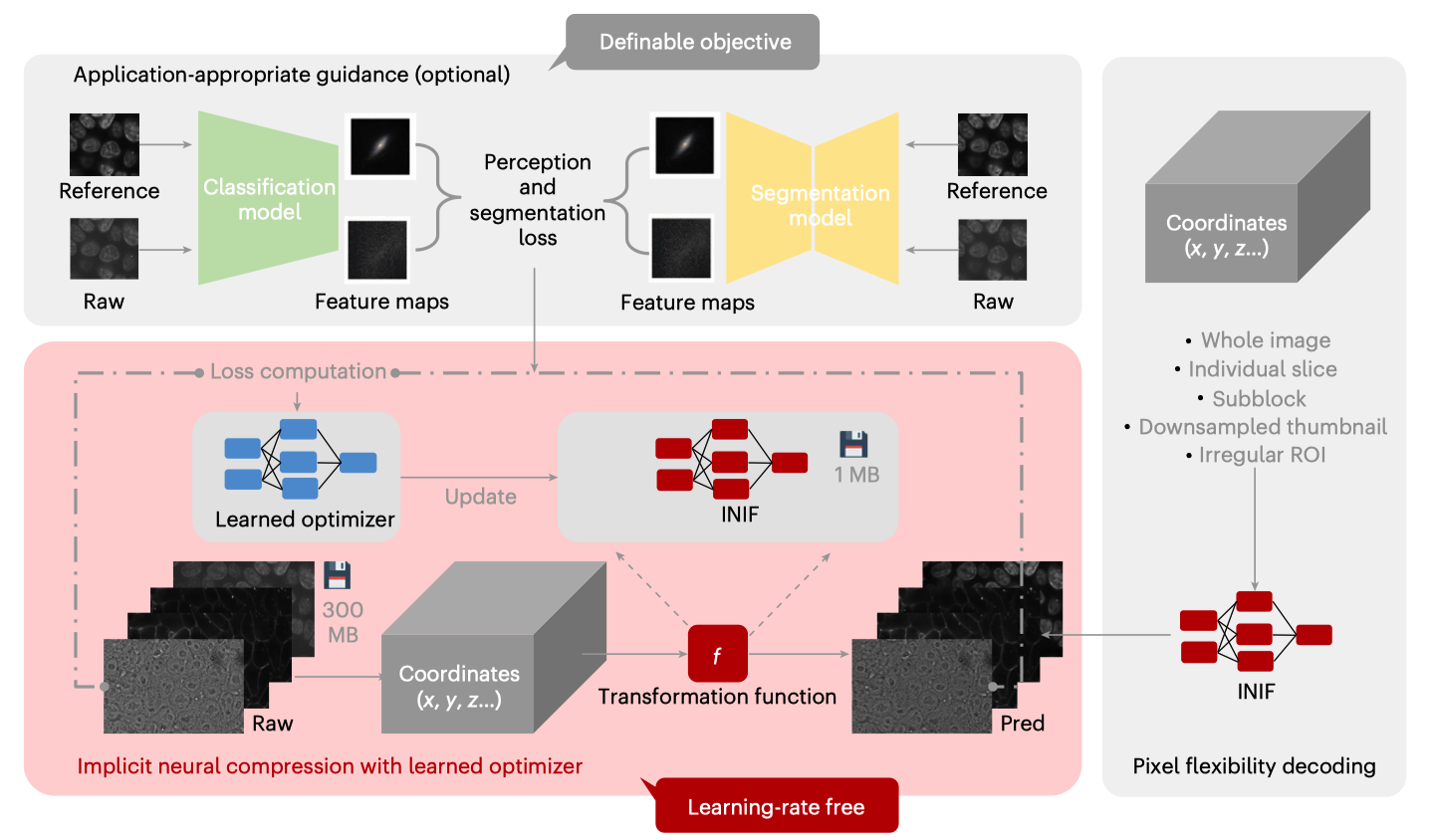
We propose an adaptive compression pipeline based on implicit neural representations (INR) that supports arbitrary-shape images and pixel-level decompression. It achieves controllable high compression ratios (up to 512x) and demonstrates effectiveness on various real biological microscopy images, significantly reducing storage and sharing burden while preserving critical analytical information.
@article{dai2025implicit,title={Implicit Neural Image Field for Biological Microscopy Image Compression},author={Dai, Gaole and Zhang, Rongyu and Wuwu, Qingpo and Tseng, Cheng-Ching and Zhou, Yu and Wang, Shaokang and Qian, Siyuan and Lu, Ming and Tuz, Ali Ata and Gunzer, Matthias and others},journal={Nature Computational Science},volume={5},number={11},pages={1041--1050},year={2025},publisher={Nature Publishing Group US New York},}
2023
arXiv
Chain of Thought Prompt Tuning in Vision Language Models
Jiaxin Ge, Hongyin Luo, Siyuan Qian, Yulu Gan, Jie Fu, and Shanghang Zhang
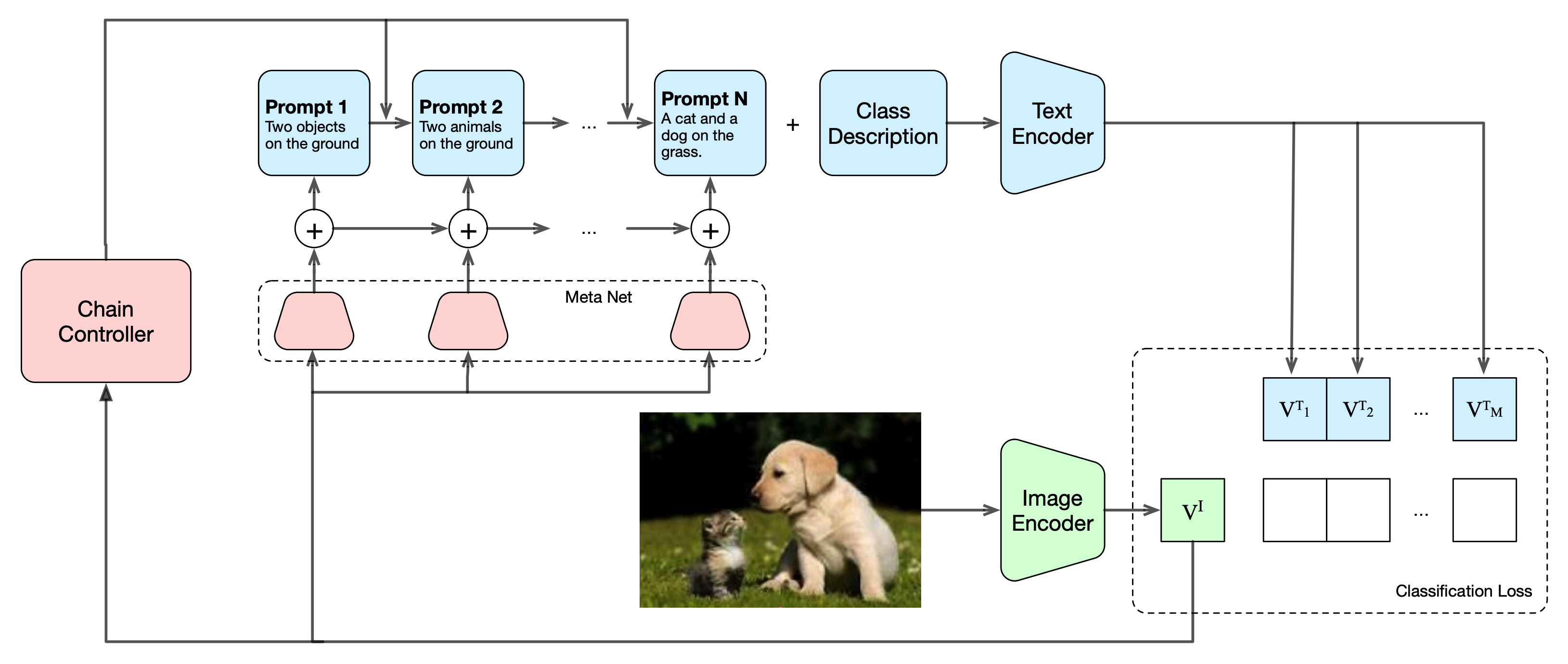
We propose a Chain-of-Thought prompt tuning method that introduces CoT into vision-language models by jointly leveraging visual and textual embedding information. This significantly improves generalization and transfer in image classification tasks, and demonstrates stronger reasoning performance in image-text retrieval and visual question answering tasks, achieving the first successful application of this method in visual tasks.
@article{ge2023cot,title={Chain of Thought Prompt Tuning in Vision Language Models},author={Ge, Jiaxin and Luo, Hongyin and Qian, Siyuan and Gan, Yulu and Fu, Jie and Zhang, Shanghang},journal={arXiv preprint arXiv:2304.07919},year={2023},}